So gelingt das Fine-Tuning von LLMs (Large Language Models) im Jahr 2025: Best Practices
Juni 24, 2025
Categories: Blockchain, Technologien



Auf dem heutigen KI-Markt findet sich eine Vielzahl großer Sprachmodelle (LLMs), die in unterschiedlichsten Ausführungen – sowohl als Open-Source- als auch als Closed-Source-Modelle – verfügbar sind und eine breite Palette an Fähigkeiten bieten.
Einige dieser Modelle sind anderen bereits deutlich überlegen (z. B. ChatGPT, Gemini, Claude, Llama und Mistral), da sie in der Lage sind, zahlreiche Aufgaben präziser und schneller zu lösen als ihre Konkurrenten.
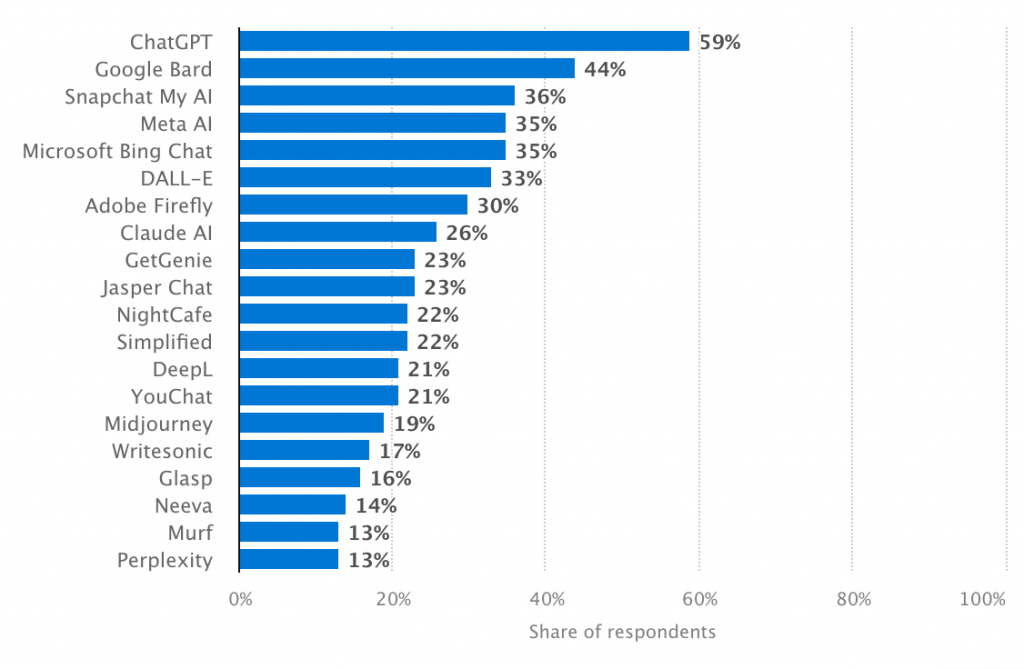
Beliebteste AI-Tools, Statista
Doch selbst diese Spitzenmodelle – so leistungsfähig sie auch sind – passen nicht immer sofort perfekt zu den Anforderungen eines Unternehmens. Die meisten Organisationen stellen schnell fest, dass breit angelegte, generische LLMs weder ihre branchenspezifische Terminologie noch interne Arbeitsabläufe oder den Markenstil zuverlässig erfassen. Genau hier kommt das Fine-Tuning ins Spiel.
Was ist Fine-Tuning und warum ist es 2025 so wichtig?
Fine-Tuning bezeichnet das gezielte Nachtrainieren eines bereits vortrainierten großen Sprachmodells mit einem kleinen, spezialisierten Datensatz. Dieser Datensatz ist auf eine bestimmte Aufgabe, Branche oder Organisation zugeschnitten.
Dabei wird ein Modell nicht von Grund auf neu trainiert, sondern seine bestehenden Fähigkeiten werden durch feine Anpassungen gezielt erweitert – etwa, um einen bestimmten Sprachstil zu erlernen oder komplexe Fachbegriffe korrekt zu verwenden.
Warum vortrainierte Modelle allein oft nicht ausreichen
LLMs werden üblicherweise auf riesigen Mengen öffentlicher Internetdaten trainiert. Dadurch sind sie zwar gut für allgemeine Aufgaben wie Textgenerierung, Übersetzung, Zusammenfassungen oder Beantwortung einfacher Fragen geeignet – bei fachspezifischen Anforderungen zeigen sich aber oft Schwächen.
Rechtliche Begriffe, medizinische Fachsprache oder wirtschaftliche Fachausdrücke werden mitunter falsch interpretiert. Die Antworten klingen oberflächlich plausibel, wirken auf Experten jedoch oft unpassend oder verwirrend.
Fine-Tuning löst dieses Problem: Ein Krankenhaus kann ein Modell so trainieren, dass es medizinische Begriffe und die Kommunikation zwischen Fachärzten versteht.
Oder ein Logistikunternehmen bringt dem Modell branchenspezifisches Wissen über Versandprozesse und Lagerverwaltung bei. Das Ergebnis: Die Antworten werden präziser, die Fachsprache korrekt, das Modell besser einsetzbar.
Vorteile des Fine-Tunings großer Sprachmodelle (LLMs) für Unternehmen
Das Fine-Tuning großer Sprachmodelle (LLMs) ermöglicht es Unternehmen, den maximalen Nutzen aus KI herauszuholen – indem die Modelle genau auf die spezifischen Anforderungen des Unternehmens abgestimmt werden.

Zunächst verleiht das Fine-Tuning dem Modell die Fähigkeit, in der „Sprache“ Ihres Unternehmens zu kommunizieren. Jedes Unternehmen hat seinen eigenen Tonfall, Stil und Ausdruck – manche sind formell und technisch, andere freundlich und nahbar. Durch überwachtes Fine-Tuning lernt das Modell, genau diesen Stil anzuwenden und bevorzugte Formulierungen zu verwenden.
Zudem verbessert das Fine-Tuning die Genauigkeit in spezialisierten Fachgebieten erheblich. So erzielte das OpenAI o1-Modell im März 2024 mit 94,8 % den höchsten Benchmark-Wert bei der Beantwortung mathematischer Aufgaben.
Als generisches Modell versteht es jedoch möglicherweise keine juristischen Fachbegriffe, medizinischen Formulierungen oder wirtschaftlichen Zusammenhänge in der Tiefe.
Wird ein Modell hingegen gezielt mit branchenspezifischen Informationen trainiert, kann es deutlich besser auf komplexe oder technische Fragen reagieren.
Ein weiterer wichtiger Vorteil ist der Datenschutz. Anstatt sensible Informationen an Drittanbieter weiterzugeben, können Unternehmen ein Modell intern anpassen und einsetzen. So bleiben vertrauliche Daten geschützt und es wird sichergestellt, dass Datenschutzrichtlinien eingehalten werden.
Schließlich kann das Fine-Tuning langfristig auch Kosten senken. Zwar erfordert es anfänglich Zeit und Ressourcen, doch ein feinabgestimmtes Modell arbeitet effizienter, macht weniger Fehler und braucht weniger Wiederholungen.
Oft ist es sogar günstiger als der wiederholte Einsatz einer kostenpflichtigen API eines allgemeinen Modells.
Top Fine-Tuning-Methoden im Jahr 2025
Das Fine-Tuning großer Sprachmodelle ist im Jahr 2025 deutlich zugänglicher und benutzerfreundlicher geworden. Unternehmen benötigen weder riesige Budgets noch tiefgehende Machine-Learning-Erfahrung, um ein Modell für ihre eigenen Anforderungen zu optimieren.

Es stehen heute zahlreiche bewährte Methoden zur Verfügung – von vollständigem Retraining bis hin zu leichten Anpassungen –, sodass Organisationen je nach Zielen, Datenlage und Infrastruktur die optimale Strategie wählen können.
Vollständiges Fine-Tuning – Die effektivste Methode
Das vollständige Fine-Tuning (Full Fine-Tuning) ist laut IBM ein Ansatz, bei dem das vorhandene Wissen des Basismodells als Ausgangspunkt genutzt wird, um es mithilfe eines kleineren, aufgabenspezifischen Datensatzes anzupassen.
Dabei werden sämtliche Modellgewichte verändert, um die Leistung auf eine konkrete Aufgabe hin zu optimieren. Diese Methode erzielt meist die besten Ergebnisse, ist jedoch rechenintensiv und ressourcenaufwendig.
LoRA und PEFT – Effizient und kostengünstig
Für Unternehmen, die eine schnellere und preisgünstigere Lösung suchen, sind LoRA (Low-Rank Adaptation) und PEFT (Parameter-Efficient Fine-Tuning) besonders attraktiv.
Diese Methoden verändern nur bestimmte Teile des Modells anstelle des gesamten Gewichtsgefüges. Sie funktionieren gut selbst bei geringem Datenvolumen und begrenzter Rechenleistung und sind deshalb ideal für Startups und mittelständische Unternehmen.
Instruction Fine-Tuning – Für bessere Aufgabenverständlichkeit
Instruction Fine-Tuning schult das Modell gezielt darauf, wie es Anweisungen versteht und ausführt. Dadurch werden die Antworten präziser, kürzer und praxisorientierter.
Diese Methode ist besonders nützlich für KI-Assistenten, die zur Unterstützung, Schulung oder Beratung eingesetzt werden.
RLHF (Reinforcement Learning from Human Feedback)
RLHF ist eine fortschrittliche Technik, die das Modell mit menschlichem Feedback trainiert. Dabei werden gute und schlechte Antworten vorgegeben – und das Modell lernt durch Belohnung optimaler Reaktionen.
Diese Methode ist komplex, aber bestens geeignet für den Einsatz in hochverantwortungsvollen Szenarien, z. B. bei KI-Rechtsassistenten oder spezialisierten Beraterlösungen.
Prompt-Tuning und Adapter – Schnell, leicht, flexibel
Wenn nur eine schnelle und unkomplizierte Anpassung benötigt wird, bieten sich Prompt-Tuning oder Adapter-Techniken an. Dabei wird das eigentliche Modell nicht verändert – stattdessen nutzt man kleine Erweiterungen oder ausgeklügelte Prompts, um das Modellverhalten gezielt zu beeinflussen.
Diese Varianten sind günstig, schnell umsetzbar und eignen sich hervorragend für Pilotprojekte oder frühe Tests
| Methode | Was sie macht | Kosten/Geschwindigkeit | Am besten geeignet für |
Vollständiges Fine-Tuning | Trainiert das gesamte Modell mit neuen Daten | Hoch / Langsam | Großprojekte mit hohen Leistungsanforderungen |
LoRA / PEFT | Passt nur ausgewählte Parameter an | Niedrig / Schnell | Startups, Teams mit begrenzten Ressourcen |
Instruction Tuning | Verbessert die Reaktion auf Benutzeranweisungen | Mittel / Moderat | KI-Assistenten, Support-Bots |
RLHF | Trainiert mit menschlichem Feedback und Belohnungssignalen | Hoch / Mittel | Experten-Systeme, sichere und zuverlässige Ausgaben |
Prompt-Tuning / Adapter | Fügt kleine Module oder Prompts hinzu, kein Retraining nötig | Sehr niedrig / Sehr schnell | Schnelle Tests, günstige Anpassungen |
Die wichtigsten Feinabstimmungsmethoden im Jahr 2025 – auf einen Blick
Was Sie 2025 für das Fine-Tuning eines Large Language Models benötigen: Best Practices
Das Fine-Tuning eines LLM ist im Jahr 2025 auch für Unternehmen ohne ML-Engineering-Team erschwinglich geworden. Um jedoch genaue und zuverlässige Ergebnisse zu erzielen, ist es wichtig, den Prozess richtig anzugehen.
Der erste Schritt besteht darin, den Modelltyp auszuwählen: Open-Source oder Closed-Source. Offene Modelle (z. B. LLaMA, Mistral) bieten mehr Möglichkeiten: Sie können auf eigenen Servern gehostet, in der Architektur angepasst und mit eigenen Daten verwaltet werden.
Geschlossene Modelle (wie GPT oder Claude) bieten hohe Leistung und Qualität, funktionieren jedoch über APIs – das bedeutet, dass keine vollständige Kontrolle möglich ist.
Wenn Datensicherheit und Flexibilität für Ihr Unternehmen entscheidend sind, sind offene Modelle vorzuziehen. Wenn jedoch eine schnelle Markteinführung und minimale technische Hürden wichtiger sind, ist ein geschlossenes Modell die bessere Wahl.
Anschließend benötigen Sie geeignete Trainingsdaten, also saubere, gut organisierte Beispiele aus Ihrem Fachgebiet, etwa E-Mails, Support-Chats, Dokumente oder andere Texte, mit denen Ihr Unternehmen arbeitet.
Je besser Ihre Daten sind, desto intelligenter und nützlicher wird das Modell nach dem Fine-Tuning. Ohne gute Daten klingt das Modell zwar gut, liegt aber oft daneben oder verfehlt den Kern.
Darüber hinaus brauchen Sie die richtigen Tools und die passende Infrastruktur. Einige Unternehmen setzen auf Plattformen wie AWS oder Google Cloud, andere hosten lokal, um maximale Privatsphäre zu gewährleisten. Zur Steuerung und Überwachung des Trainingsprozesses können Tools wie Hugging Face oder Weights & Biases verwendet werden.
Natürlich funktioniert all das nicht ohne die richtigen Fachkräfte. Für das Fine-Tuning werden in der Regel ein Machine Learning Engineer (zum Trainieren des Modells), ein DevOps-Experte (für Systemeinrichtung und -betrieb) sowie ein Fachexperte oder Business Analyst (um die Lerninhalte des Modells zu definieren) benötigt. Wenn ein solches Team nicht vorhanden ist, kann dessen Aufbau zeitaufwendig und kostspielig sein.
Deshalb arbeiten viele Unternehmen heute mit Outsourcing-Partnern zusammen, die sich auf die Entwicklung von maßgeschneiderter KI-Software spezialisiert haben. Diese Partner übernehmen den gesamten technischen Ablauf – von der Modellauswahl und Datenaufbereitung bis hin zu Training, Testing und Deployment.
Business-Anwendungsfälle für feinjustierte LLMs
Feinjustierte Modelle sind nicht nur intelligenter, sondern auch besser für reale Geschäftsanwendungen geeignet. Wenn ein Modell mit unternehmenseigenen Daten trainiert wird, übernimmt es deren Wesenskern und liefert dadurch wertvolle, präzise Ergebnisse statt allgemeiner Antworten.

KI-Kundensupport-Agenten
Statt eines generischen Chatbots kann ein Support-Agent entwickelt werden, der mit Ihren Produkten, Dienstleistungen und Richtlinien vertraut ist. Er antwortet wie ein geschulter menschlicher Mitarbeiter – mit dem richtigen Ton und aktuellen Informationen.
Personalisierte virtuelle Assistenten
Ein gut trainiertes Modell kann spezifische Aufgaben übernehmen, etwa Bestellungen bearbeiten, HR-Fragen beantworten, Interviews vorbereiten oder Sendungen verfolgen. Diese Assistenten lernen aus Ihren internen Dokumenten und Systemen und wissen genau, wie Dinge in Ihrem Unternehmen ablaufen.
Enterprise-Wissensmanagement
In großen Unternehmen gibt es oft zu viele Dokumente, Handbücher und Richtlinien, um den Überblick zu behalten.
Ein optimiertes LLM kann all diese Informationen durchforsten und Mitarbeitern innerhalb von Sekunden einfache Antworten liefern. Das spart Zeit und erleichtert den Zugriff auf benötigtes Wissen, ohne in Dateien oder PDFs wühlen zu müssen.
Domänenspezifische Copiloten (Recht, Medizin, E-Commerce)
Spezialisierte Copiloten können Fachkräfte in ihrem täglichen Arbeitsumfeld unterstützen:
- Juristen erhalten Unterstützung beim Überprüfen von Verträgen oder Zusammenfassen von Fällen.
- Ärzt:innen können das Modell nutzen, um Notizen zu erstellen oder Patientenakten schneller zu erfassen.
- E-Commerce-Teams können Produktbeschreibungen generieren, Kataloge aktualisieren oder Kundenbewertungen analysieren.
Case Study: Smart Travel Guide
Eines der besten Beispiele für feinjustierte Modelle ist der Smart Travel Guide AI. Er wurde darauf trainiert, Reisenden personalisierte Tipps auf Basis ihrer Vorlieben, ihres Standorts und lokaler Events zu geben. Anstatt generische Empfehlungen zu liefern, erstellt er individuelle Routen und Vorschläge.
Herausforderungen beim Fine-Tuning von LLMs
Das Fine-Tuning eines LLM ist im Allgemeinen sehr nützlich, bringt aber manchmal auch einige Herausforderungen mit sich.

Die erste große Hürde ist das Vorhandensein ausreichender Daten. Ein Modell lässt sich nur feinjustieren, wenn viele saubere, strukturierte und wertvolle Trainingsbeispiele vorhanden sind.
Wenn Ihr Datensatz unorganisiert, unzureichend oder voller Fehler ist, wird das Modell möglicherweise nicht das lernen, was Sie eigentlich brauchen. Anders gesagt: Wenn Sie Müll hineingeben, bekommen Sie auch Müll heraus – egal wie fortschrittlich das Modell ist.
Hinzu kommt der Kostenfaktor für das Training und den Betrieb des Modells. Solche Modelle benötigen enorme Rechenressourcen, besonders wenn es sich um große Modelle handelt.
Doch die Ausgaben enden nicht mit dem Training. Auch Testläufe, Anpassungen und die kontinuierliche Überprüfung der Leistung sind erforderlich, um sicherzustellen, dass das Modell dauerhaft gut funktioniert.
Ein weiteres Problem ist Overfitting – also wenn das Modell die Trainingsdaten zu perfekt lernt und nichts darüber hinaus. Es liefert dann zwar während des Tests gute Antworten, versagt jedoch bei neuen oder auch nur leicht abweichenden Fragen.
Genauso wichtig sind rechtliche und ethische Aspekte. Wenn Ihr Modell Ratschläge gibt, sensible Daten verarbeitet oder Entscheidungen trifft, ist besondere Vorsicht geboten.
Sie müssen sicherstellen, dass es keine Voreingenommenheiten aufweist, keine schädlichen Inhalte erzeugt und Datenschutzgesetze wie DSGVO oder HIPAA einhält.
So starten Sie mit dem LLM-Fine-Tuning
Wenn Sie über Fine-Tuning nachdenken, ist die gute Nachricht: Sie müssen nicht blind einsteigen. Mit dem richtigen Ansatz kann es ein unkomplizierter und sehr lohnender Prozess sein.

Zunächst sollten Sie Ihren Business Case prüfen. Fragen Sie sich: Müssen Sie wirklich ein Modell feinjustieren – oder reicht intelligentes Prompt Engineering (also gezieltes Schreiben von Eingabeaufforderungen) aus, um die gewünschten Ergebnisse zu erzielen? Für viele einfache Aufgaben oder Bereiche ist Prompt Engineering schneller und günstiger.
Wenn Sie jedoch mit branchenspezifischem Vokabular, festgelegtem Tonfall oder vertraulichen Daten arbeiten, ist Fine-Tuning oft die bessere langfristige Lösung.
Entscheiden Sie als Nächstes, ob Sie das Projekt intern umsetzen oder mit einem externen Partner zusammenarbeiten wollen. Der Aufbau eines eigenen KI-Teams gibt Ihnen zwar volle Kontrolle, kostet aber Zeit, Budget und erfordert spezielles Know-how.
Ein Outsourcing-Partner wie SCAND kann dagegen den gesamten technischen Prozess übernehmen: von der Auswahl des Modells und der Datenaufbereitung über das Fine-Tuning bis hin zur Bereitstellung – einschließlich Unterstützung beim Prompt Engineering.
Bevor Sie loslegen, stellen Sie sicher, dass Ihr Unternehmen vorbereitet ist. Sie brauchen ausreichend saubere Daten, klare Ziele für das Modell und eine Methode zur Leistungsmessung.
Vergessen Sie auch nicht den Datenschutz und die Compliance. Wenn Ihr Modell mit vertraulichen, rechtlichen oder medizinischen Daten arbeitet, muss es alle relevanten Vorschriften einhalten.
Wie SCAND helfen kann
Wenn Ihnen das Know-how oder die Zeit fehlen, das Projekt intern durchzuführen, übernimmt SCAND den gesamten Prozess für Sie.
Wir helfen Ihnen bei der Auswahl des passenden KI-Modells für Ihr Unternehmen – sei es ein Open-Source-Modell wie LLaMA oder Mistral oder ein Closed-Source-Modell wie GPT oder Claude. Anschließend bereiten wir Ihre Daten professionell auf.
Dann übernehmen wir den Rest: das Fine-Tuning des Modells, die Bereitstellung in der Cloud oder auf Ihren Servern sowie das Monitoring der Modellleistung – mit dem Ziel, dass es verständlich kommuniziert und gut funktioniert.
Wenn Sie zusätzlichen Schutz benötigen, bieten wir auch lokales Hosting zur Sicherung Ihrer Daten und zur Einhaltung gesetzlicher Vorschriften – oder Sie entscheiden sich für unsere LLM-Entwicklungsservices, um ein exklusiv für Sie entwickeltes KI-Modell zu erhalten.
FAQ
F: Was genau bedeutet das Fine-Tuning eines LLM?
A: Fine-Tuning bedeutet, ein vortrainiertes Sprachmodell mit Ihren eigenen Daten weiter zu trainieren, sodass es Ihre Branche, Sprache oder Markenstimme besser versteht und wiedergibt.
F: Kann ich nicht einfach ein vortrainiertes Modell verwenden?
A: Doch, das geht – allerdings sind vortrainierte Modelle allgemein gehalten und kommen mit Nischenthemen oder speziellen Tonlagen oft nicht gut zurecht. Fine-Tuning ermöglicht präzisere und relevantere Ergebnisse.
F: Wie viele Daten brauche ich für das Fine-Tuning?
A: Das hängt von Ihren Anforderungen und der Modellgröße ab. Grundsätzlich gilt: Je mehr qualitativ hochwertige und gut gelabelte Daten, desto besser die Ergebnisse.
F: Ist Fine-Tuning teuer?
A: Es kann teuer sein – insbesondere bei großen Modellen – und erfordert laufende Wartung. Doch auf lange Sicht rentiert es sich durch geringere API-Kosten und eine verbesserte Nutzererfahrung.
Author Bio

